AlphaGo
AlphaGo is a computer program developed at DeepMind that plays the board game Go, and was the first computer program to beat a professional Go player - a decade before expected.

AlphaGo is a computer program developed at DeepMind that plays the board game Go, and was the first computer program to beat a professional Go player - a decade before expected.
TrueSkill is a skill rating for games that generalises the popular Elo rating system known from chess to include uncertainty estimates of player ratings, to allow for estimating individual ratings from team outcomes even with more than two teams. TrueSkill was first used in the Xbox 360 title Halo 3 and has since been used by a variety of Xbox 360 titles.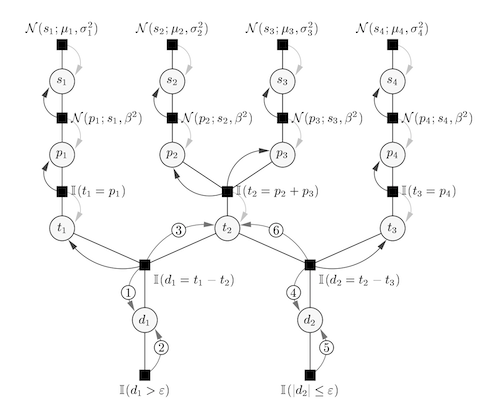
Published in NeurIPS, 2007
We present a new Bayesian skill rating system which can be viewed as a generalisation of the Elo system used in Chess. The new system tracks the uncertainty about player skills, explicitly models draws, can deal with any number of competing entities and can infer individual skills from team results. Inference is performed by approximate message passing on a factor graph representation of the model. We present experimental evidence on the increased accuracy and convergence speed of the system compared to Elo and report on our experience with the new rating system running in a large-scale commercial online gaming service under the name of TrueSkill.
Recommended citation: Ralf Herbrich, Tom Minka, Thore Graepel. (2007). "TrueSkill(TM): a Bayesian skill rating system." Advances in Neural Information Processing Systems. pages 569-576. http://papers.nips.cc/paper/3079-trueskilltm-a-bayesian-skill-rating-system.pdf
Published in International Conference on Machine Learning (ICML), 2010
We describe a new Bayesian click-through rate (CTR) prediction algorithm used for Sponsored Search in Microsoft's Bing search engine. The algorithm is based on a probit regression model that maps discrete or real-valued input features to probabilities. It maintains Gaussian beliefs over weights of the model and performs Gaussian online updates derived from approximate message passing. Scalability of the algorithm is ensured through a principled weight pruning procedure and an approximate parallel implementation. We discuss the challenges arising from evaluating and tuning the predictor as part of the complex system of sponsored search where the predictions made by the algorithm decide about future training sample composition. Finally, we show experimental results from the production system and compare to a calibrated Naïve Bayes algorithm.
Recommended citation: Thore Graepel, Joaquin Quinonero-Candela, Thomas Borchert, Ralf Herbrich. (2010). "Web-Scale Bayesian click-through rate prediction for sponsored search advertising in Microsofts Bing search engine" Proceedings of the 27th International Conference on Machine Learning (ICML-10). pages 13-20. https://www.microsoft.com/en-us/research/wp-content/uploads/2010/06/AdPredictor-ICML-2010-final.pdf
Published in Proceedings of the National Academy of Sciences of the United States of America, 2013
We show that easily accessible digital records of behavior, Facebook Likes, can be used to automatically and accurately predict a range of highly sensitive personal attributes including: sexual orientation, ethnicity, religious and political views, personality traits, intelligence, happiness, use of addictive substances, parental separation, age, and gender. The analysis presented is based on a dataset of over 58,000 volunteers who provided their Facebook Likes, detailed demographic profiles, and the results of several psychometric tests. The proposed model uses dimensionality reduction for preprocessing the Likes data, which are then entered into logistic/linear regression to predict individual psychodemographic profiles from Likes. The model correctly discriminates between homosexual and heterosexual men in 88% of cases, African Americans and Caucasian Americans in 95% of cases, and between Democrat and Republican in 85% of cases. For the personality trait “Openness,” prediction accuracy is close to the test–retest accuracy of a standard personality test. We give examples of associations between attributes and Likes and discuss implications for online personalization and privacy.
Recommended citation: Michal Kosinski, David Stillwell, and Thore Graepel. (2013). "Private traits and attributes are predictable from digital records of human behavior." Proceedings of the National Academy of Sciences of the United States of America (PNAS). 110 (15) 5802-5805. https://www.pnas.org/content/pnas/110/15/5802.full.pdf
Published in Nature, 2016
The game of Go has long been viewed as the most challenging of classic games for artificial intelligence owing to its enormous search space and the difficulty of evaluating board positions and moves. Here we introduce a new approach to computer Go that uses ‘value networks’ to evaluate board positions and ‘policy networks’ to select moves. These deep neural networks are trained by a novel combination of supervised learning from human expert games, and reinforcement learning from games of self-play. Without any lookahead search, the neural networks play Go at the level of state-of-the-art Monte Carlo tree search programs that simulate thousands of random games of self-play. We also introduce a new search algorithm that combines Monte Carlo simulation with value and policy networks. Using this search algorithm, our program AlphaGo achieved a 99.8% winning rate against other Go programs, and defeated the human European Go champion by 5 games to 0. This is the first time that a computer program has defeated a human professional player in the full-sized game of Go, a feat previously thought to be at least a decade away.
Recommended citation: David Silver, Aja Huang, Chris J. Maddison, Arthur Guez, Laurent Sifre, George van den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, Sander Dieleman, Dominik Grewe, John Nham, Nal Kalchbrenner, Ilya Sutskever, Timothy Lillicrap, Madeleine Leach, Koray Kavukcuoglu, Thore Graepel & Demis Hassabis. (2016). "Mastering the game of Go with deep neural networks and tree search." Nature. 529, pages 484–489. https://storage.googleapis.com/deepmind-media/alphago/AlphaGoNaturePaper.pdf
Published in Nature, 2017
A long-standing goal of artificial intelligence is an algorithm that learns, tabula rasa, superhuman proficiency in challenging domains. Recently, AlphaGo became the first program to defeat a world champion in the game of Go. The tree search in AlphaGo evaluated positions and selected moves using deep neural networks. These neural networks were trained by supervised learning from human expert moves, and by reinforcement learning from self-play. Here we introduce an algorithm based solely on reinforcement learning, without human data, guidance or domain knowledge beyond game rules. AlphaGo becomes its own teacher: a neural network is trained to predict AlphaGo’s own move selections and also the winner of AlphaGo’s games. This neural network improves the strength of the tree search, resulting in higher quality move selection and stronger self-play in the next iteration. Starting tabula rasa, our new program AlphaGo Zero achieved superhuman performance, winning 100–0 against the previously published, champion-defeating AlphaGo.
Recommended citation: David Silver, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou, Aja Huang, Arthur Guez, Thomas Hubert, Lucas Baker, Matthew Lai, Adrian Bolton, Yutian Chen, Timothy Lillicrap, Fan Hui, Laurent Sifre, George Van Den Driessche, Thore Graepel, Demis Hassabis. (2017). "Mastering the game of Go without human knowledg." Nature. 550(7676), pages 354-359. https://discovery.ucl.ac.uk/id/eprint/10045895/1/agz_unformatted_nature.pdf
Published in Science, 2018
The game of chess is the longest-studied domain in the history of artificial intelligence. The strongest programs are based on a combination of sophisticated search techniques, domain-specific adaptations, and handcrafted evaluation functions that have been refined by human experts over several decades. By contrast, the AlphaGo Zero program recently achieved superhuman performance in the game of Go by reinforcement learning from self-play. In this paper, we generalize this approach into a single AlphaZero algorithm that can achieve superhuman performance in many challenging games. Starting from random play and given no domain knowledge except the game rules, AlphaZero convincingly defeated a world champion program in the games of chess and shogi (Japanese chess), as well as Go.
Recommended citation: David Silver, Thomas Hubert, Julian Schrittwieser, Ioannis Antonoglou, Matthew Lai, Arthur Guez, Marc Lanctot, Laurent Sifre, Dharshan Kumaran, Thore Graepel, Timothy Lillicrap, Karen Simonyan, Demis Hassabis. (2018). "A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play." Science. Vol. 362, Issue 6419, pp. 1140-1144. https://science.sciencemag.org/content/sci/362/6419/1140.full.pdf
Published in Science, 2019
Reinforcement learning (RL) has shown great success in increasingly complex single-agent environments and two-player turn-based games. However, the real world contains multiple agents, each learning and acting independently to cooperate and compete with other agents. We used a tournament-style evaluation to demonstrate that an agent can achieve human-level performance in a three-dimensional multiplayer first-person video game, Quake III Arena in Capture the Flag mode, using only pixels and game points scored as input. We used a two-tier optimization process in which a population of independent RL agents are trained concurrently from thousands of parallel matches on randomly generated environments. Each agent learns its own internal reward signal and rich representation of the world. These results indicate the great potential of multiagent reinforcement learning for artificial intelligence research.
Recommended citation: Max Jaderberg, Wojciech M. Czarnecki, Iain Dunning, Luke Marris, Guy Lever, Antonio Garcia Castañeda, Charles Beattie, Neil C. Rabinowitz, Ari S. Morcos, Avraham Ruderman, Nicolas Sonnerat, Tim Green, Louise Deason, Joel Z. Leibo, David Silver, Demis Hassabis, Koray Kavukcuoglu, Thore Graepel. (2019). "Human-level performance in 3D multiplayer games with population-based reinforcement learning." Science. Vol. 364, Issue 6443, pp. 859-865. https://science.sciencemag.org/content/sci/364/6443/859.full.pdf
Published:
videolectures.net site Requires Adobe Flash Player
Published:
Published:
Tutorial Site and Slides (or here)
Lecture Series, University College London (UCL), 2020
Over the past decade, Deep Learning has evolved as the leading artificial intelligence paradigm providing us with the ability to learn complex functions from raw data at unprecedented accuracy and scale.